在傳統水泥工業面臨能耗高、管理粗放、安全環保壓力日益增大的背景下,智慧工廠的建設已成為行業轉型升級的必然選擇。物聯網技術作為智慧工廠的核心支撐,通過構建一個感知互聯、數據驅動、智能決策的新型生產體系,為水泥領域帶來了全方位、深層次的解決方案。
一、 整體架構:構建“端-邊-云”協同的物聯神經網絡
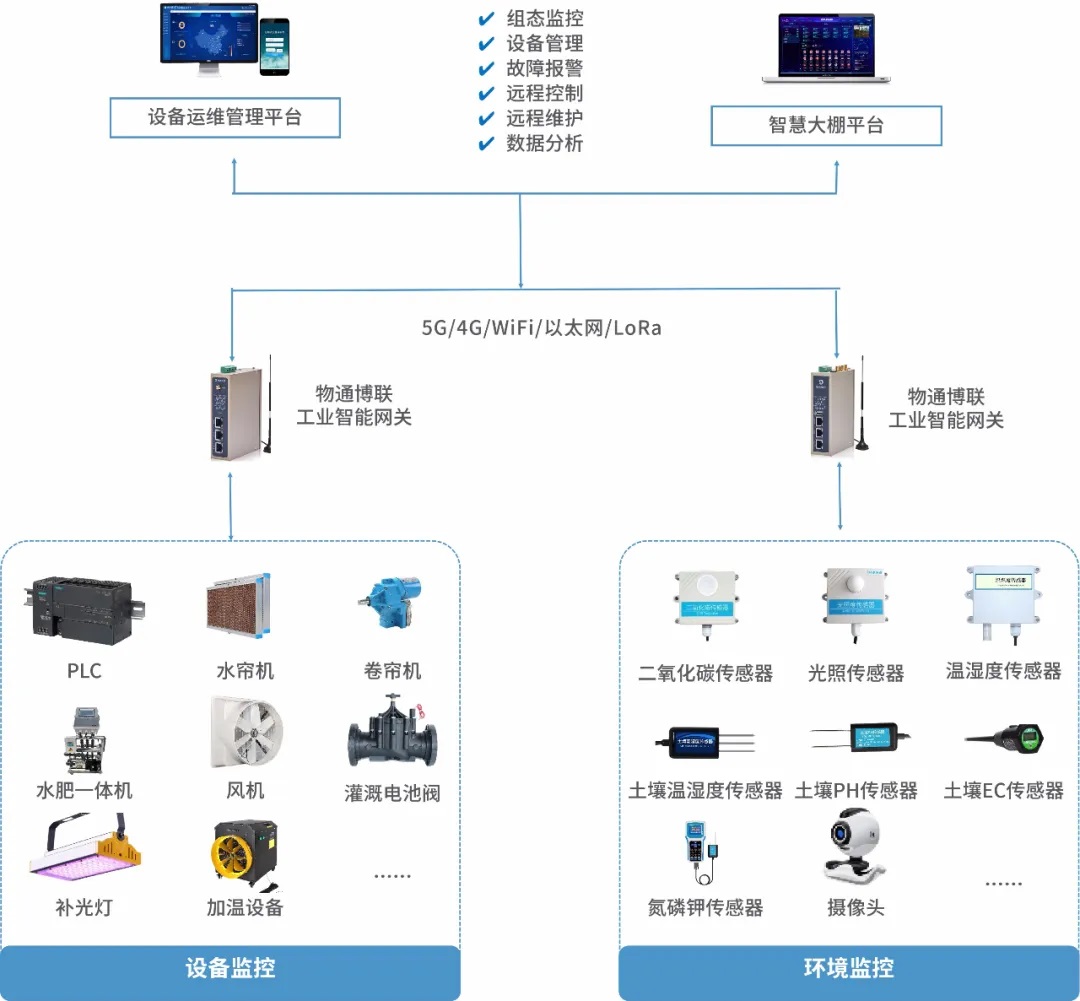
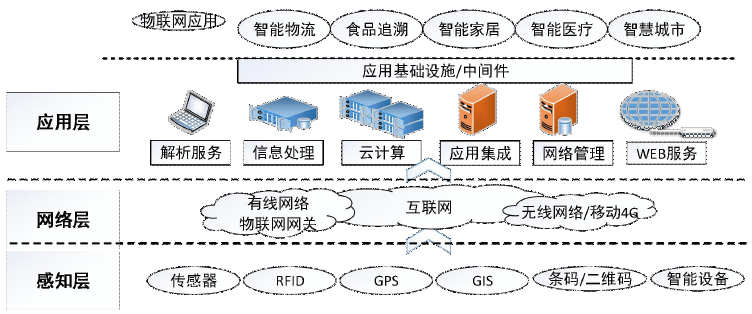
水泥智慧工廠的物聯網解決方案通常采用“端-邊-云”三層協同架構。
- 感知層(端):在生產關鍵節點部署大量智能傳感器、RFID標簽、智能儀表、高清攝像頭等終端設備,實時采集設備運行狀態(如立磨、回轉窯的振動、溫度、壓力)、生產參數(如生料配比、燒成溫度)、能耗數據(電、煤消耗)、環保指標(粉塵、NOx排放)以及人員、物資的位置信息,實現全要素、全流程的數字化感知。
- 網絡與邊緣層(邊-網):利用工業以太網、5G、LoRa、Wi-Fi 6等多種網絡技術,構建高可靠、低時延的融合通信網絡,確保海量數據穩定傳輸。在靠近生產現場的邊緣側部署邊緣計算網關或服務器,對實時性要求高的數據進行本地預處理、分析和緩存,實現設備的快速閉環控制(如緊急停機)和實時預警,減輕云端壓力,提升響應速度。
- 平臺與應用層(云):數據匯聚至工業物聯網云平臺,進行集中存儲、深度整合與建模分析。平臺通過數字孿生技術,構建工廠虛擬映像,實現物理世界與信息世界的精準映射。基于大數據與AI算法,開發各類智能應用,如預測性維護、智能質量控制、能耗優化、安全智能管控、供應鏈協同等,為管理決策提供科學依據。
二、 核心應用場景:物聯網技術驅動的價值落地
物聯網技術服務深度融入水泥生產核心環節,創造顯著價值。
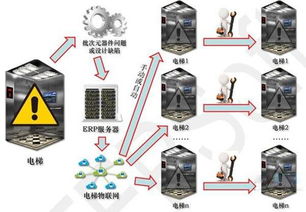
- 設備健康管理與預測性維護:通過對大型主機設備(如窯、磨)的振動、溫度、電流等參數進行連續監測,結合歷史數據與AI模型,精準預測零部件故障發生概率與剩余壽命,變“事后維修”為“事前維護”,大幅減少非計劃停機,降低維護成本,延長設備生命周期。
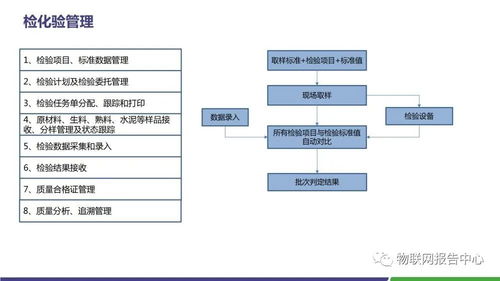
- 生產過程優化與質量控制:實時監測生料配料、熟料燒成、水泥粉磨等關鍵工藝參數,通過算法模型動態優化控制設定值,確保工藝穩定在最佳狀態。在線質量分析儀與物聯網結合,實現產品質量(如細度、強度)的實時反饋與閉環控制,提升產品一致性與優等品率。
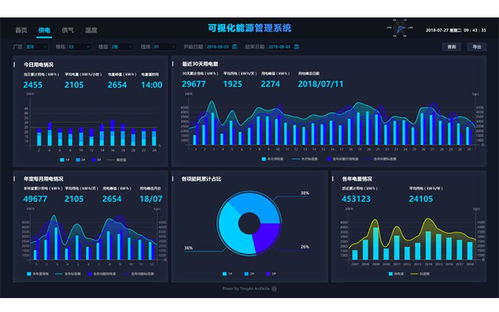
- 能源管理與節能降耗:建立全廠能源計量網絡,實時監測各環節、各設備的電、煤消耗。通過數據分析,識別能耗異常與浪費點,并結合工藝優化模型,給出針對性的節能建議與自動控制策略,助力企業實現“雙碳”目標。
- 安全環保智能監控:利用物聯網傳感器、視頻AI識別技術,對廠區危險區域(如窯頭、煤磨)、人員不安全行為(如未佩戴安全帽、闖入危險區)、環保排放口進行7x24小時智能監控與預警。實現有毒有害氣體泄漏早期探測、粉塵超標自動報警、車輛清洗與排放合規性自動核查,全面提升安全環保管理水平。
- 智能倉儲與物流調度:通過物聯網技術實現原料堆場、熟料庫、水泥庫的庫存實時盤點與三維可視化。結合GPS/RFID技術,對進出廠車輛進行智能調度、自動稱重、無人值守裝車,極大提高物流效率,減少車輛等待時間與人為干預。
三、 實施路徑與關鍵考量
成功部署水泥智慧工廠物聯網解決方案,需遵循“總體規劃、分步實施、業務驅動”的原則。
- 基礎設施先行:評估并升級現有工業網絡,確保其具備承載海量物聯網數據的能力。選擇兼容性強、可靠性高的傳感器與邊緣設備。
- 數據整合與平臺建設:打破“數據孤島”,通過物聯網平臺整合DCS、PLC、SCADA等原有系統數據,以及新增的物聯網數據,構建統一的數據底座。
- 場景化應用開發:優先選擇痛點明顯、投資回報率高的場景(如關鍵設備預測性維護、能源管理)進行試點,取得成效后逐步推廣。
- 安全與標準:必須將工業網絡安全貫穿始終,確保數據采集、傳輸、存儲、應用全過程的安全。關注并遵循行業相關數據標準與協議,保證系統的開放性與可擴展性。
- 組織與人才:智慧工廠不僅是技術變革,更是管理變革。需要配套調整組織流程,并培養或引入兼具水泥工藝知識與物聯網、數據分析技能的復合型人才。
水泥領域的智慧工廠物聯網解決方案,正將這一傳統“灰黑”產業帶入“綠色智能”的新紀元。它通過無處不在的連接、洞察一切的數據和智能化的決策,實現了生產效率和效益的躍升、安全環保風險的可控、以及運營模式的根本性創新。對于水泥企業而言,積極擁抱物聯網技術,構建智慧工廠,已不再是可選項,而是在未來市場競爭中贏得先機的核心競爭力。專業的物聯網技術服務商,將作為可靠的伙伴,為企業提供從咨詢規劃、方案設計、系統集成到持續運維的全生命周期服務,共同推動水泥工業的高質量、可持續發展。